Introduction
Counting items in a table is simple for small datasets, it gets more challenging at larger datasets. It is even more challenging if the data should be fresh and the answer should come in 30ms.
In this article, I go through the different ways to count items in a database table. This post will use PostgreSQL (PG) as an example. PG counts slower than other RDBMS like Oracle due to the specifics of the PostgreSQL MVCC implementation. Nevertheless, the general ideas apply to other OLTP databases as well.
Simple Count
Even if it is slightly outdated, this is the seminal article from Citus to explore counting performance in PostgreSQL. Most of it the topics discussed still apply.
Counting in a row store like PostgreSQL can become increasingly slow because of the physical data organization on disk.
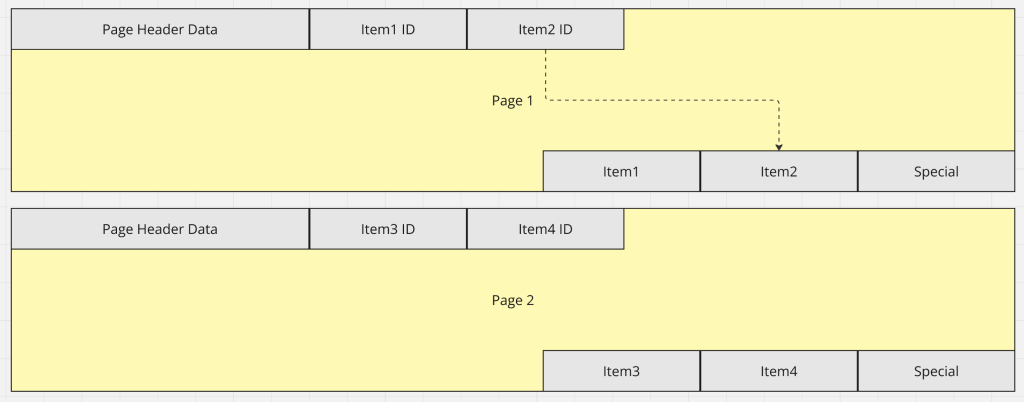
Row stores use the slotted page structure to physically store records. This structure makes it clearly visible why counting gets slow. The entire table has to be scanned to know the number of items.
This problem is further amplified by the fill factor, which means that not every page will be full. In PG it is 100% by default, but OLTP operations improve performance if the fill-factor is reduced to 80%.
This means that a lot of unnecessary data is read from disk.
The Trade-Offs
A common question is: why doesn’t PostgreSQL keep simple statistics about the number of items in the page? Well… because of MVCC in PostgreSQL it is not that easy to answer:
- Which tuples are alive from the point of the current transaction?
- Which tuples are alive for any of the still running transactions?
By default all items have to be looked at. The system has to know whether the current transaction should count an item. Performance can be improved by the visibility map. That removes to need to look at every record one by one. This works if all the records of a given page are visible.
That means: if we want to count accurately, then all records have to be read. We can cache or approximate though. Counting becomes a trade-off between latency, throughput and data freshness.
Other approaches
There are other ways to count in a row store. I will try to order them from lightweight to heavyweight.
Parallel Worker Count
Check if you database has the right amount of parallel workers configured in terms of your CPU cores. This can be an easy win.
Case Statements or PostgreSQL Filters
SQL case statements or PostgreSQL filters are a good way to reduce the number of passes over the data. They effectively combine multiple where statements into a single query execution.
This can be very helpful to count rows based on different criterias without doing a full group by. For example.

Use Index-Only Scan
Because indexes are contiguous in pages, it practically comes closer to column storage. That is faster than scanning the actual tuples.
This solution delivers an accurate count on non-NULL columns that are indexed. This approach requires us to read a smaller subset of all the columns.
Another limitation is that NULL values won’t be counted. This solution does not work if there are NULLs in the table or there are multi-column filters in the query.
Example use case
A good use-case is counting the number of posts for the logged-in user on a forum. If the user id is indexed, then it is a single count operation, which can be done with an index-only scan.
Limitations
- Be aware that NULL values are not counted at count. Except with the * operator.
- Works with only with “where” clauses if the index specifically matched the filtering criteria.
- Generally this approach scales linearly with the number of rows as well.
Use a Database Trigger
A counter in a separate metadata table can be updated using a trigger. There is added complexity to handle deletes as well if needed.
This method is accurate and it can be queried quickly, but it will have scaling limitations due to lock syncs. This can be optimized by having 4-5 counting rows and randomly distributing the trigger between them to minimize lock contention.
Materialized Views
Update a materialized view every few minutes with the count of the tables. It is a workable async approach if stale results are tolerated. Internally a background worker runs a query to populate a virtual table for the results.
A limitation of materialized views is that the entire data is scanned at every refresh time. There are approaches for incremental view updates, but I don’t know how well developed they are. In any case, they need specific extensions.
An equivalent solution is to have a table that is populated by a scheduled query. That can be messier though since there is no direct relationship to the original table, only implicitly through the query.
Roll-Up Tables
A classic solution for counting is roll-up tables. They can be combined with
Citus wrote a good blogpost about roll-up tables in PostgreSQL in 2018.
There is a good blogpost from them about the trade-offs between materialized views and roll-up tables.
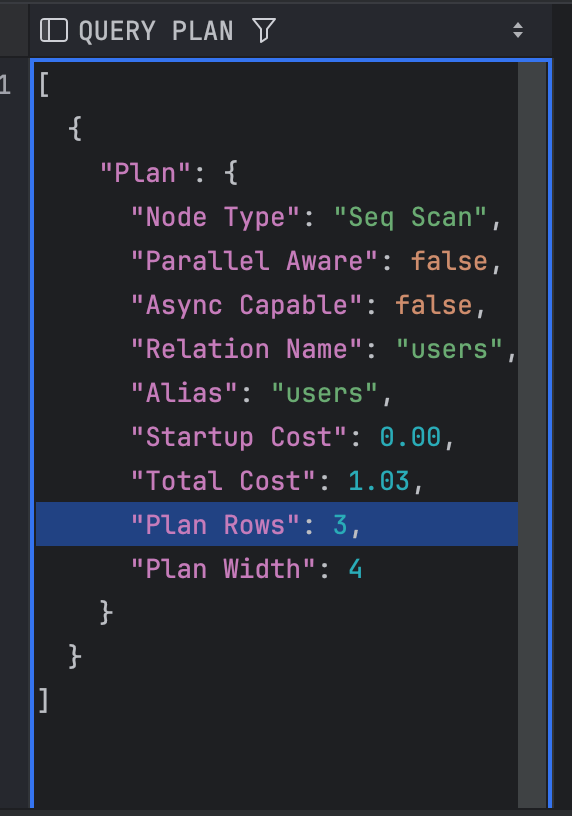
Use Row Estimates Statistics
If only an estimated value is needed, then row estimates might be a good approximation. This approach is not exact, but it is super lightweight.
Be aware that it needs regular and correct analyze commands in PostgreSQL to make it work properly.

Limitations:
- Does not works with a where clause in the query very well. Multi-column filtering is not possible at all. With a single column filter it highly depends on the database statistics.
- Requires well-tuned autovacuum to be reasonably accurate.
Internal Column Store
There is a new DuckDB extension to PostgreSQL that might be worth looking at. It creates an internal column store representation to better serve analytical queries.
Other databases like Oracle also have similar solutions, this mixing is called HTAP( Hybrid Transactional/Analytical Processing). It means that a database is comparatively good with both OLAP and OLTP workloads. Of course, as a combined system, it has more constraints than pure solutions for each workload.
This paper gives a great overview of different HTAP approaches.
External Column Store
If there is a data warehouse around, like Redshift, then it can be considered for counting items. The columnar representation of data warehouses makes counting much faster, but it also adds complexity to the application. The eventual consistency between the OLTP workload and the OLAP service can be a deal-breaker as well.
HyperLogLog Extension
There are extensions for PostgreSQL to maintain a probabilistic approximation for table cardinality using a HLL data structure.
Never had much to do with probabilistic data structures? Don’t worry, here there are some good talks as an introduction. You might have already heard about some of them: HyperLogLog, Bloom Filters and Cuckoo Filter.
There is a good post from Citus about combining HLL with roll-up tables for efficient scalable counting in Postgres.
Other Resources
But let me just leave here a few great resources that I found in the topic for later reference:
